

Charlie Baptista
“At our bank, we rely heavily on automated data testing capabilities of stardq to resurface bad data and remediate it.”
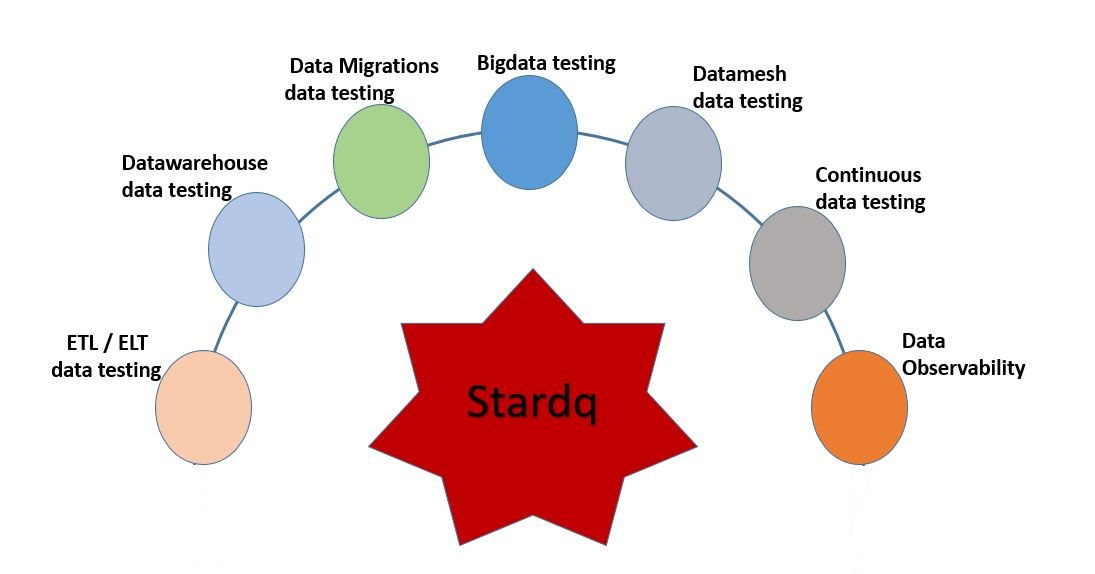
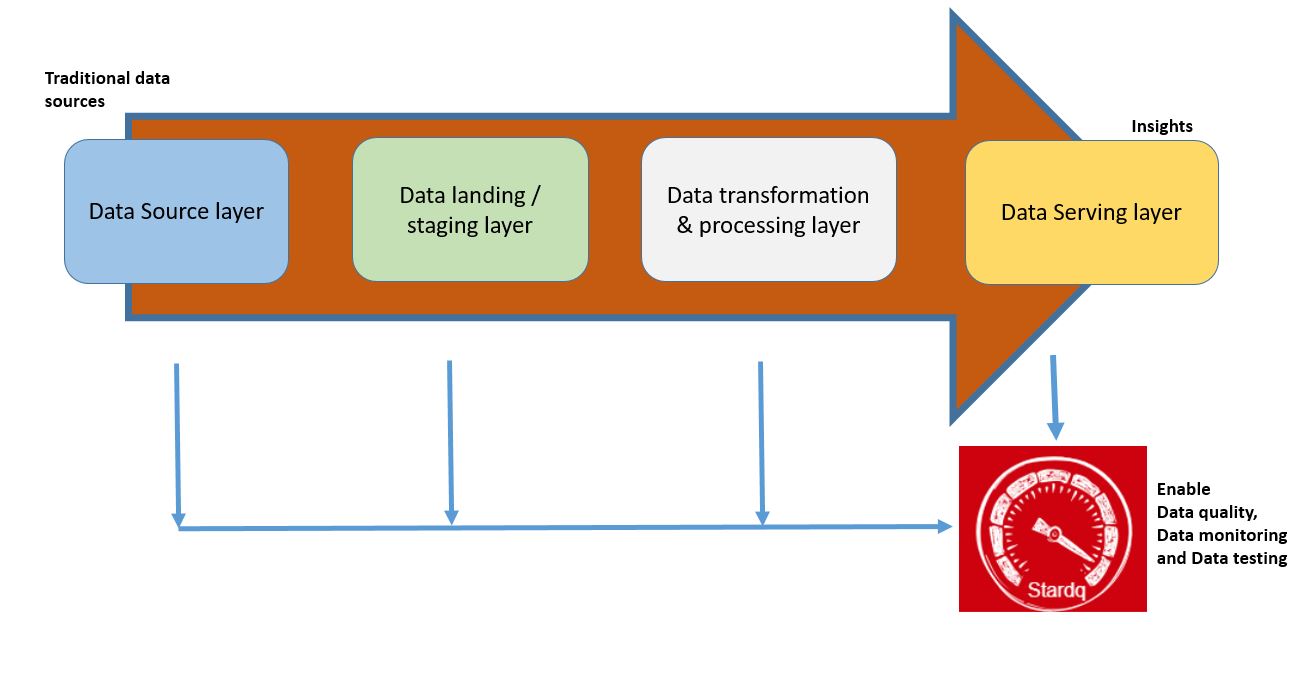
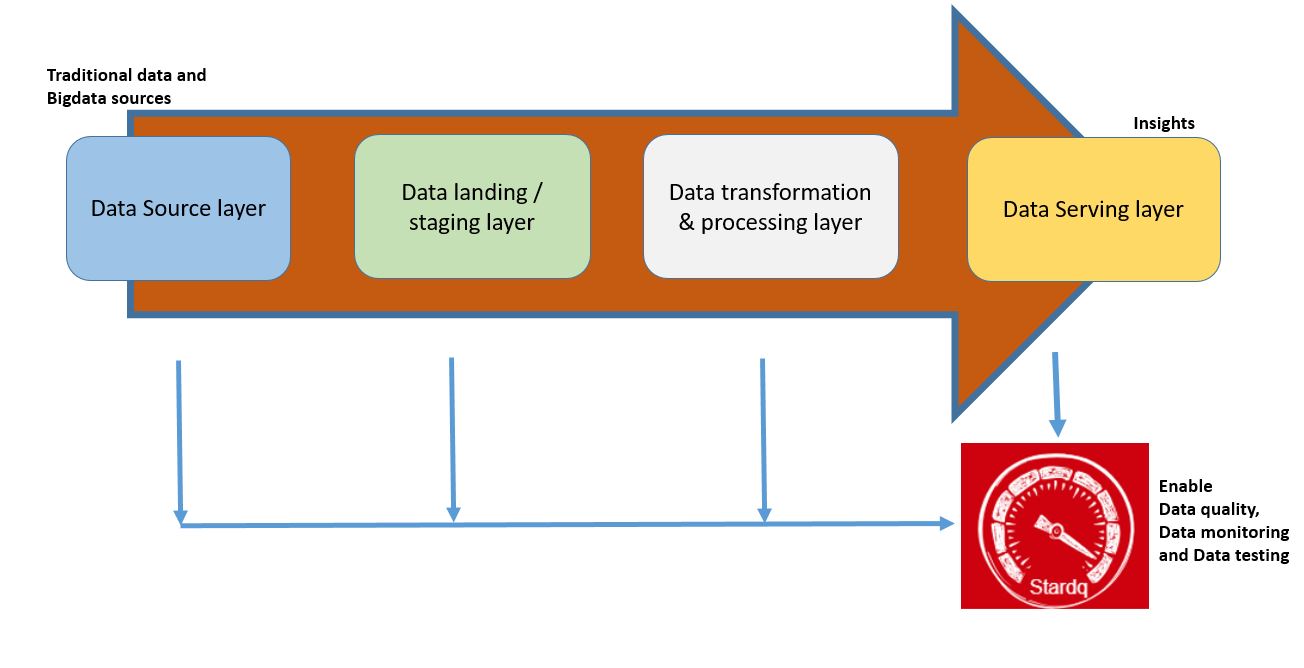
The platform uses defined expectations to validate data and capture validation results in metrics repository.

Adam Smith
“We use automated data testing and quality capabilities of stardq to resurface data anomalies and enhance data quality.”
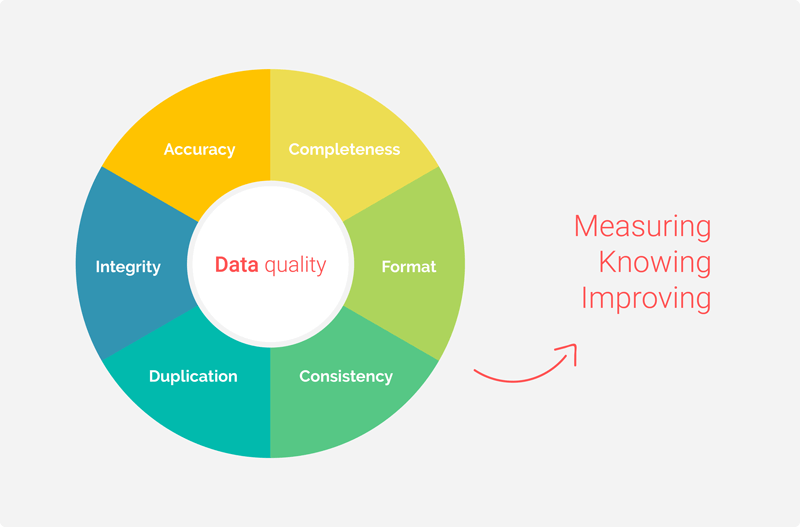
The platform provides data quality and validation reports and dashboard to understand data quality issues and remediate it.